Today I made a very simple implementation of Q-learning algorithm that learns a tabular function using first-visit, constant alpha updates, and Monte Carlo rollouts based on an epsilon-greedy policy. I applied this to the FrozenLake environment. Here’s a plot showing the environment the optimal policy and the full Q table.
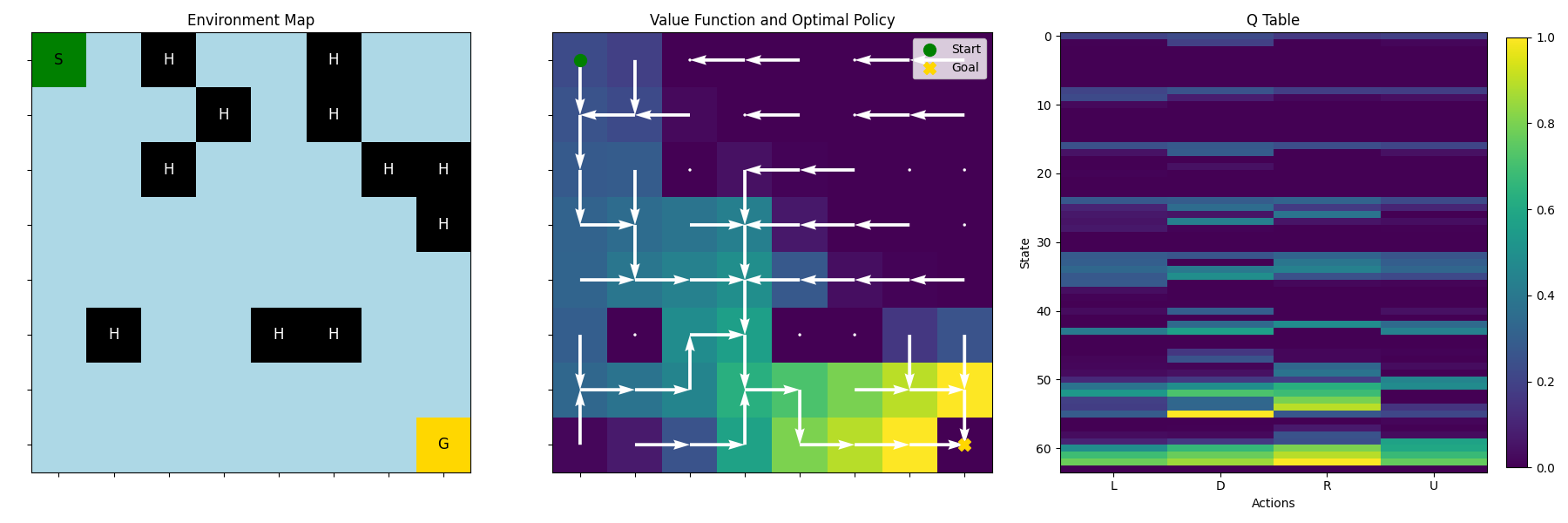
Find the code here.