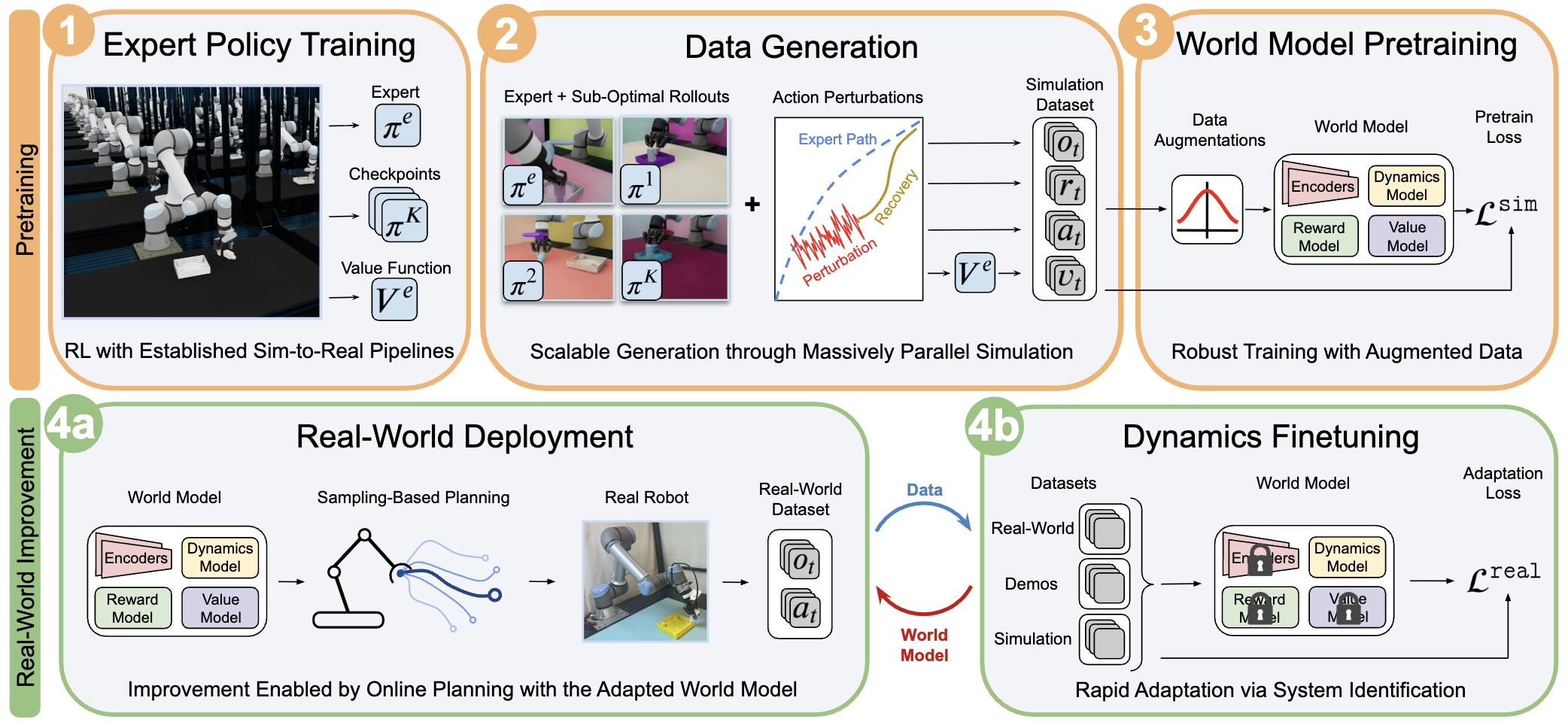
TLDR: Simulation Distillation distills reward and value models from simulation into a latent world model, then adapts to the real world via online planning and short-horizon dynamics finetuning.
The problem
Sim-to-real finetuning with RL struggles with exploration and long-horizon credit assignment when data is scarce.
The solution
Transfer reward and value functions from simulation into a world model before deployment. Real-world adaptation then reduces to short-horizon system identification, avoiding long-horizon credit assignment. Tested on manipulation and locomotion tasks, outperforming prior sim-to-real methods in data efficiency and final performance.