I’ve been looking into ways of incorporating epistemic uncertainty into learned world models in a way that fits nicely with a control problem. David suggested I look into combining neural networks with Gaussian processes (GPs) like Harrison et al. in Variational Bayesian Last Layers or Meta-Learning Priors for Efficient Online Bayesian Regression (ALPaCA). This work looks super interesting, but once I started digging into it I realized I didn’t really understand how GPs really worked, so in this post I’ll derive GPs, explain what ALPaCA is, and show an implementation of ALPaCA in JAX.
This is meant mostly for me to understand the material better, but maybe you’ll find it useful too.
Gaussian Processes (GPs)
Definition
Consider a supervised learning problem, where we have a set of
Gaussian processes are different because they produce estimates over functions instead of parameters.
That is, instead of estimating the most likely
To do so, we start by defining a prior distribution over functions that’s conditioned on the training data
Then, we assume this prior is a Gaussian with mean
and
Outputs are jointly Gaussian
Assuming the prior over functions is Gaussian implies the outputs
are distributed according to a joint Gaussian distribution with mean and covariance . That is, . This is a strong assumption, but it is useful because it allows us to easily compute the posterior distribution over functions given training data (as we will see later) and therefore make predictions.
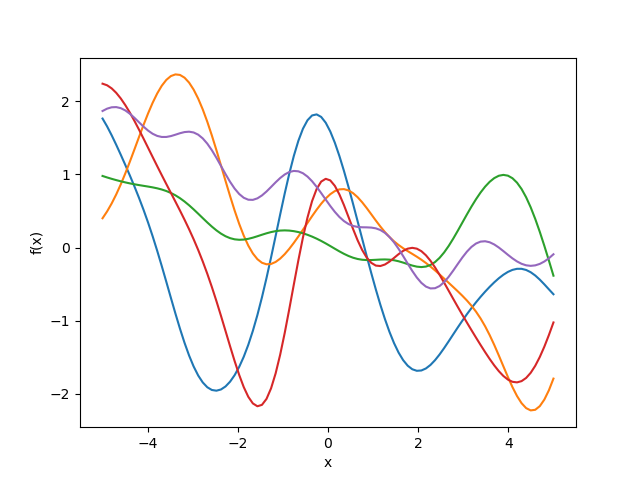
We can sample the prior to get an idea what the functions look like before seeing the data.
To do this, we define a set of
Prediction
Given training data consisting of inputs
Recall we assumed that function outputs are jointly Gaussian. Therefore, we can write the joint distribution of the training and test outputs as
where
Below is a plot of sampled functions from a posterior distribution given a set using a squared exponential kernel with
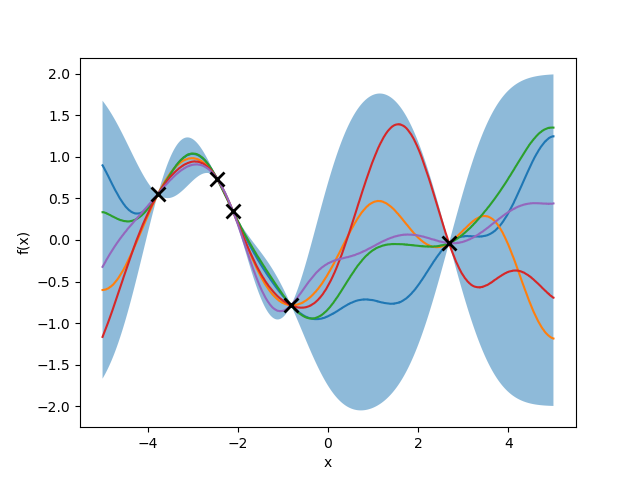
In practice, observations are noisy. I will not cover that case here, but the derivation conditional distribution is very similar and can be found in Ch. 15 of Murphy’s Probabilistic ML.
Meta-Learning Priors (ALPaCA)
Notation
I don’t have infinite time so in this section I’ll mostly follow the notation Harrison et al. used in Meta-Learning Priors for Efficient Online Bayesian Regression (ALPaCA). Read carefully, as there may be differences in notation and definitions from the previous sections.
Now that we (hopefully) understand GPs, let’s see what Harrison et al. did with them in ALPaCA. First, I’ll work through some preliminaries to understand the problem formulation and Bayesian regression. Then, I’ll talk about ALPaCA’s algorithm, where the meta-learning is happening, and share my JAX implementation. Finally, I’ll discuss how ALPaCA can be interpreted as an approximation of a GP.
Formulation
Consider a function
Given a prior over the latent parameters, i.e.,
Unfortunately, this integral is intractable because we don’t have analytic expressions for
Instead, let’s use a surrogate model
We consider a scenario in which the data comes in as a stream: at each timestep, the agent is given a new input
In this setting, the problem of learning the surrogate model can be formulated as
Note that we don’t know
Unfortunately, this expected objective is intractable because need access to
Bayesian Regression
ALPaCA uses Bayesian linear regression to compute
where
Therefore, the likelihood of the data is given by
Now let’s select the prior for
The posterior distribution is then given by
where
Now we have a posterior over
ALPaCA in JAX
In ALPaCA, the basis functions are outputs of a neural network and we do a Bayesian regression on a linear transformation applied to the final output of the network. Then, we have two phases:
- Phase 1 (offline): learn the basis functions (the neural network weights
) and the prior parameters and using a sample of datasets. - Phase 2 (online): Update the posterior parameters
and as new data comes in.
Phase 1 is where the “meta-learning” happens: we learn a prior that works well for all expected datasets. Since our prior is optimized in Phase 1, we can easily adapt to new data without having to retrain the neural network (Phase 2). Additionally, we also get live, calibrated, uncertainty estimates for every predictions. Below are the algorithms for the two phases, taken directly from the paper (note equation numbers are different from the ones I used above).


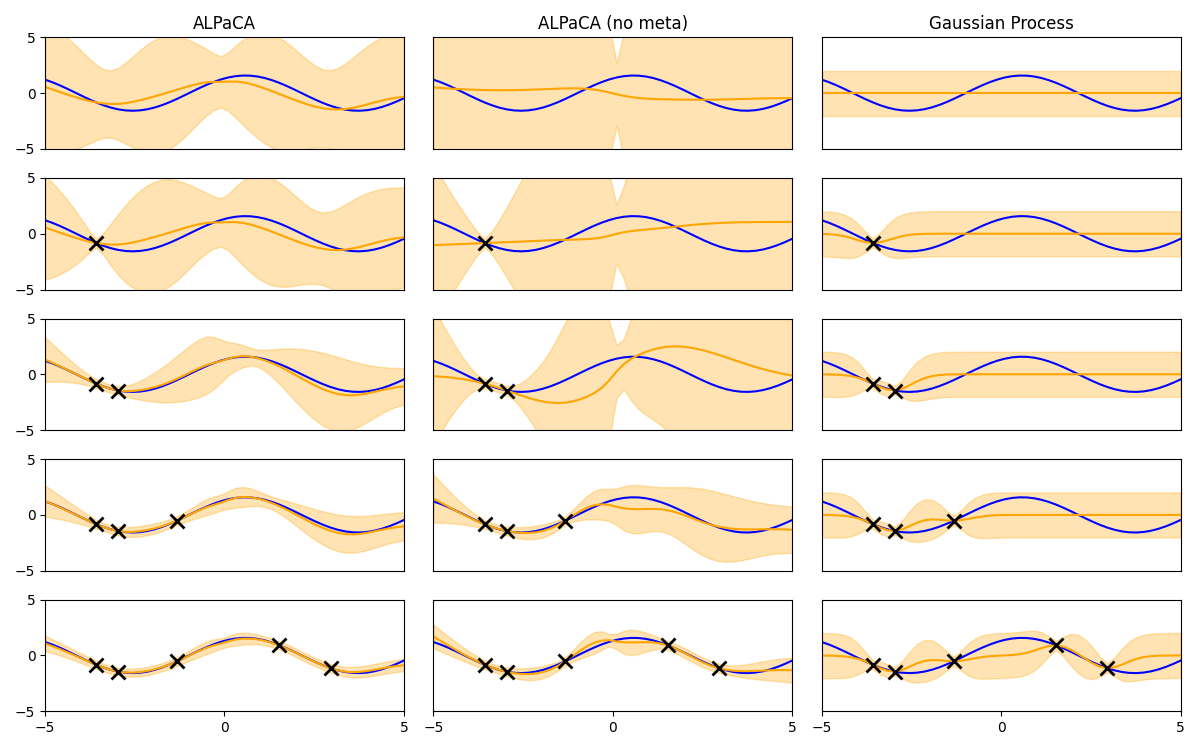
I wrote an implementation of ALPaCA in JAX and you can find it here. Below is my reproduction of Figure 2 in the paper. The plot shows predictive performance for a sinusoidal function as a function of the number of training samples. Rows correspond to different number of training samples and columns correspond to different methods. As you can see, ALPaCA (first column) is able to make some pretty good predictions even with few samples.
Connection to GP’s
Bayesian linear regression can be thought of as a GP with a kernel that’s a function of the prior
Resources
- Murphy’s Probabilistic ML
- Rasmussen’s Gaussian Processes for Machine Learning
- ALPaCA paper: Meta-Learning Priors for Efficient Online Bayesian Regression
- My JAX implementation of ALPaCA: ALPaCA
Footnotes
-
For the development of GPs, we will refer to functions as a finite-dimensional vector of function values at a set of input points. Technically, functions are infinitely-dimensional objects that require an infinite number of (input,output) pairs to be fully described (unless we have an explicit functional form for a function, e.g.,
). However, when working with GPs we are able to describe functions with a finite number of points because we assume that function values at different points are correlated. This correlation is defined according to a selected kernel function. However, the underlying function is still infinite-dimensional. Disclaimer: I’m still trying to wrap my head around these details. But I think this is the gist of it. ↩